Investing AI Terminal
// experiment notebook · not for sale · published as-is
Hypothesis
If you wire an Australian retail portfolio (AUD-denominated, momentum + dividend + venture buckets) to a news + VIP + geo signal pipeline scored by multiple LLMs, does the AI-led signal beat the SPY benchmark over a multi-month live run?
Current state (honest)
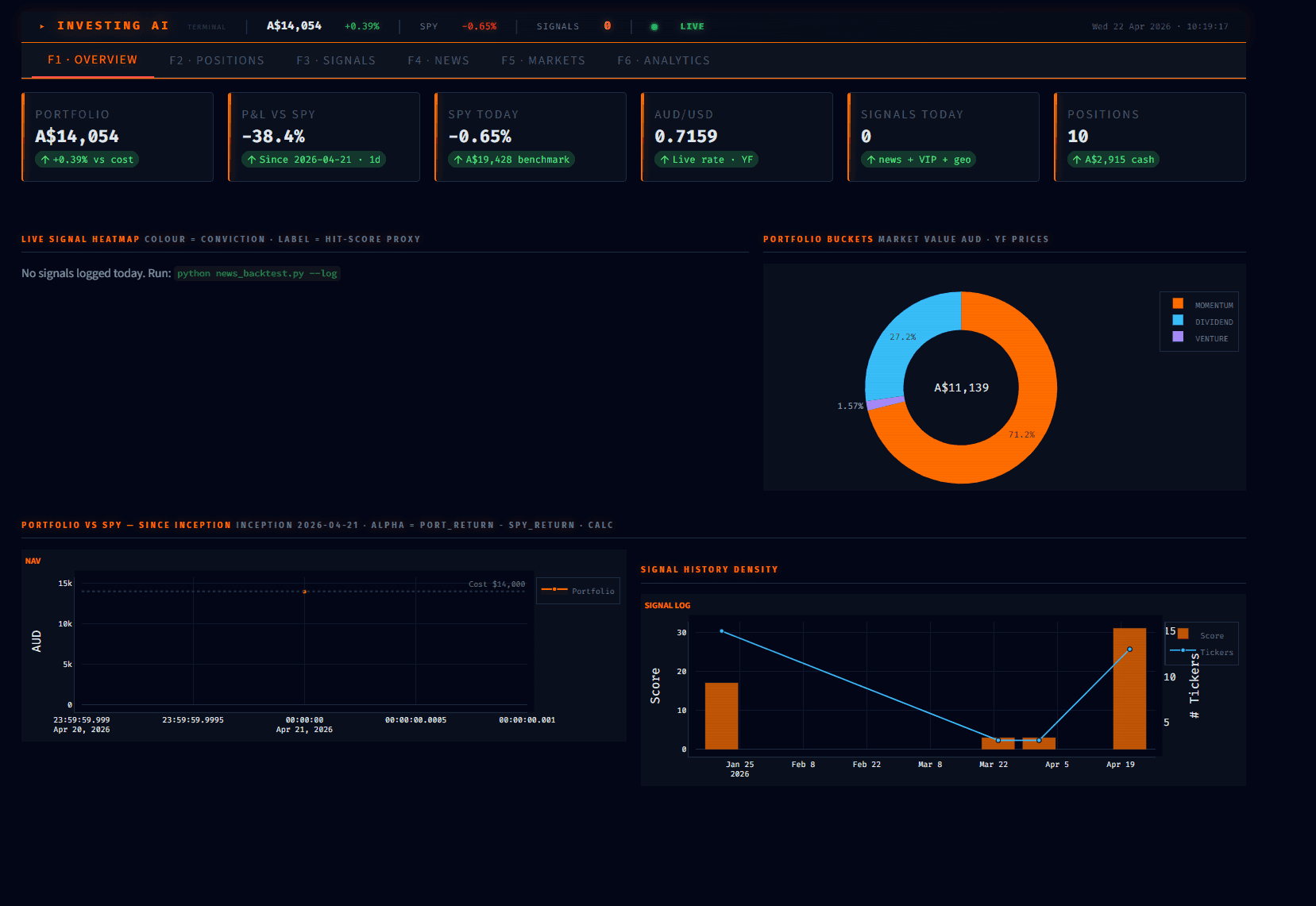
Down 38.4% vs SPY since inception. The terminal is honest about this. Most companies would hide a losing run. We publish it because the point of the lab is not to make money in retail equities, it is to stress-test how different AI models score news signals against a real ledger.
What we are testing
- 01Claude Sonnet for news signal scoring
- 02Claude Opus for cross-signal reconciliation (news + VIP + geo)
- 03Claude Haiku for fast headline screening
- 04Gemini for sentiment delta on AU vs US news
- 05Open-model baselines from Hugging Face for comparison
- 06Manual VIP-signal weighting (specific operators we trust to call inflection points)
- 07Geo-signal correlation (regional indicators against AUD/USD)
- 08Editorial operator UI as a forcing function for signal explainability
What it has taught us (transfers to client work)
Three things we have learned that DO transfer back to the day job. One: AI scoring of news is overconfident if you do not penalise it for novelty. Two: multi-model consensus catches errors single models miss, which is why every Gibson production system runs two-model review. Three: the discipline of publishing the ledger forces honesty. We apply that same discipline to client reporting now.
Running since April 2026. Internal only. Not productised. Not for sale.